Student-Teacher Network Training Guide in PyTorch
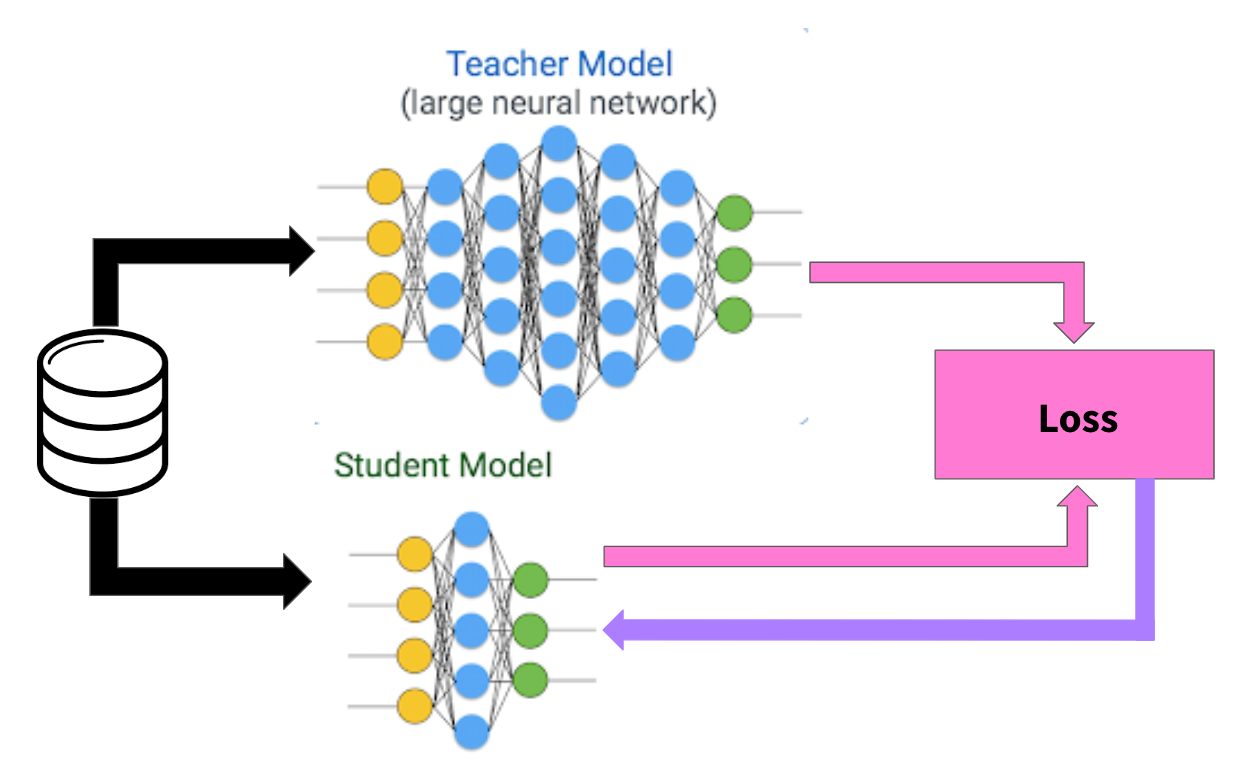
Overview
Student-teacher networks, also known as knowledge distillation, involve training a smaller “student” model to mimic the behavior of a larger, pre-trained “teacher” model. This technique helps compress large models while maintaining performance.
Key Concepts
Knowledge Distillation Loss
The student learns from both:
- Hard targets: Original ground truth labels
- Soft targets: Teacher’s probability distributions (softened with temperature)
Temperature Scaling
Higher temperature values create softer probability distributions, making it easier for the student to learn from the teacher’s uncertainty.
Complete Implementation
Import Libraries
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import numpy as npSet device
# Set device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")Define Teacher Model
class TeacherNetwork(nn.Module):
"""Large teacher network (e.g., ResNet-50 equivalent)"""
def __init__(self, num_classes=10):
super(TeacherNetwork, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(256, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return xDefine Student Model
class StudentNetwork(nn.Module):
"""Smaller student network"""
def __init__(self, num_classes=10):
super(StudentNetwork, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(128, 64),
nn.ReLU(inplace=True),
nn.Linear(64, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return xDefine Distillation Loss
class DistillationLoss(nn.Module):
"""
Knowledge Distillation Loss combining:
1. Cross-entropy loss with true labels
2. KL divergence loss with teacher predictions
"""
def __init__(self, alpha=0.7, temperature=4.0):
super(DistillationLoss, self).__init__()
self.alpha = alpha # Weight for distillation loss
self.temperature = temperature
self.ce_loss = nn.CrossEntropyLoss()
self.kl_loss = nn.KLDivLoss(reduction='batchmean')
def forward(self, student_logits, teacher_logits, labels):
# Cross-entropy loss with true labels
ce_loss = self.ce_loss(student_logits, labels)
# Soft targets from teacher
teacher_probs = F.softmax(teacher_logits / self.temperature, dim=1)
student_log_probs = F.log_softmax(student_logits / self.temperature, dim=1)
# KL divergence loss
kl_loss = self.kl_loss(student_log_probs, teacher_probs) * (self.temperature ** 2)
# Combined loss
total_loss = (1 - self.alpha) * ce_loss + self.alpha * kl_loss
return total_loss, ce_loss, kl_lossLoad and Preprocess Data
def load_data(batch_size=128):
"""Load CIFAR-10 dataset"""
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
train_dataset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
test_dataset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
return train_loader, test_loaderTrain Teacher Model
def train_teacher(model, train_loader, test_loader, epochs=50, lr=0.001):
"""Train the teacher network"""
print("Training Teacher Network...")
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
model.train()
best_acc = 0.0
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(train_loader, desc=f'Teacher Epoch {epoch+1}/{epochs}')
for batch_idx, (inputs, targets) in enumerate(progress_bar):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar.set_postfix({
'Loss': f'{running_loss/(batch_idx+1):.4f}',
'Acc': f'{100.*correct/total:.2f}%'
})
# Evaluate
test_acc = evaluate_model(model, test_loader)
print(f'Teacher Epoch {epoch+1}: Train Acc: {100.*correct/total:.2f}%, Test Acc: {test_acc:.2f}%')
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), 'teacher_best.pth')
scheduler.step()
print(f'Teacher training completed. Best accuracy: {best_acc:.2f}%')
return modelTrain Student Model with Distillation
def train_student(student, teacher, train_loader, test_loader, epochs=100, lr=0.001):
"""Train the student network using knowledge distillation"""
print("Training Student Network with Knowledge Distillation...")
distillation_loss = DistillationLoss(alpha=0.7, temperature=4.0)
optimizer = optim.Adam(student.parameters(), lr=lr, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
teacher.eval() # Teacher in evaluation mode
student.train()
best_acc = 0.0
for epoch in range(epochs):
running_loss = 0.0
running_ce_loss = 0.0
running_kl_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(train_loader, desc=f'Student Epoch {epoch+1}/{epochs}')
for batch_idx, (inputs, targets) in enumerate(progress_bar):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
# Get predictions from both networks
with torch.no_grad():
teacher_logits = teacher(inputs)
student_logits = student(inputs)
# Calculate distillation loss
total_loss, ce_loss, kl_loss = distillation_loss(
student_logits, teacher_logits, targets
)
total_loss.backward()
optimizer.step()
# Statistics
running_loss += total_loss.item()
running_ce_loss += ce_loss.item()
running_kl_loss += kl_loss.item()
_, predicted = student_logits.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar.set_postfix({
'Loss': f'{running_loss/(batch_idx+1):.4f}',
'CE': f'{running_ce_loss/(batch_idx+1):.4f}',
'KL': f'{running_kl_loss/(batch_idx+1):.4f}',
'Acc': f'{100.*correct/total:.2f}%'
})
# Evaluate
test_acc = evaluate_model(student, test_loader)
print(f'Student Epoch {epoch+1}: Train Acc: {100.*correct/total:.2f}%, Test Acc: {test_acc:.2f}%')
if test_acc > best_acc:
best_acc = test_acc
torch.save(student.state_dict(), 'student_best.pth')
scheduler.step()
print(f'Student training completed. Best accuracy: {best_acc:.2f}%')
return studentTrain Student Model Baseline
def train_student_baseline(student, train_loader, test_loader, epochs=100, lr=0.001):
"""Train student without distillation (baseline comparison)"""
print("Training Student Network (Baseline - No Distillation)...")
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(student.parameters(), lr=lr, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
student.train()
best_acc = 0.0
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(train_loader, desc=f'Baseline Epoch {epoch+1}/{epochs}')
for batch_idx, (inputs, targets) in enumerate(progress_bar):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = student(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar.set_postfix({
'Loss': f'{running_loss/(batch_idx+1):.4f}',
'Acc': f'{100.*correct/total:.2f}%'
})
# Evaluate
test_acc = evaluate_model(student, test_loader)
print(f'Baseline Epoch {epoch+1}: Train Acc: {100.*correct/total:.2f}%, Test Acc: {test_acc:.2f}%')
if test_acc > best_acc:
best_acc = test_acc
torch.save(student.state_dict(), 'student_baseline_best.pth')
scheduler.step()
print(f'Baseline training completed. Best accuracy: {best_acc:.2f}%')
return studentEvaluate Model
def evaluate_model(model, test_loader):
"""Evaluate model accuracy"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
accuracy = 100. * correct / total
model.train()
return accuracyCount Parameters
def count_parameters(model):
"""Count trainable parameters"""
return sum(p.numel() for p in model.parameters() if p.requires_grad)Main Execution
# Load data
train_loader, test_loader = load_data(batch_size=128)
# Initialize networks
teacher = TeacherNetwork(num_classes=10).to(device)
student_distilled = StudentNetwork(num_classes=10).to(device)
student_baseline = StudentNetwork(num_classes=10).to(device)
print(f"Teacher parameters: {count_parameters(teacher):,}")
print(f"Student parameters: {count_parameters(student_distilled):,}")
print(f"Compression ratio: {count_parameters(teacher) / count_parameters(student_distilled):.1f}x")
# Train teacher (or load pre-trained)
try:
teacher.load_state_dict(torch.load('teacher_best.pth'))
print("Loaded pre-trained teacher model")
except FileNotFoundError:
print("Training teacher from scratch...")
teacher = train_teacher(teacher, train_loader, test_loader, epochs=50)
teacher_acc = evaluate_model(teacher, test_loader)
print(f"Teacher accuracy: {teacher_acc:.2f}%")
# Train student with knowledge distillation
student_distilled = train_student(
student_distilled, teacher, train_loader, test_loader, epochs=100
)
# Train student baseline (without distillation)
student_baseline = train_student_baseline(
student_baseline, train_loader, test_loader, epochs=100
)
# Final evaluation
distilled_acc = evaluate_model(student_distilled, test_loader)
baseline_acc = evaluate_model(student_baseline, test_loader)
print("\n" + "="*50)
print("FINAL RESULTS")
print("="*50)
print(f"Teacher accuracy: {teacher_acc:.2f}%")
print(f"Student (distilled): {distilled_acc:.2f}%")
print(f"Student (baseline): {baseline_acc:.2f}%")
print(f"Distillation improvement: {distilled_acc - baseline_acc:.2f}%")
print(f"Parameters reduction: {count_parameters(teacher) / count_parameters(student_distilled):.1f}x")Advanced Techniques
1. Feature-Level Distillation
class FeatureDistillationLoss(nn.Module):
"""Distillation using intermediate feature maps"""
def __init__(self, alpha=0.5, beta=0.3, temperature=4.0):
super().__init__()
self.alpha = alpha # Weight for prediction distillation
self.beta = beta # Weight for feature distillation
self.temperature = temperature
self.ce_loss = nn.CrossEntropyLoss()
self.kl_loss = nn.KLDivLoss(reduction='batchmean')
self.mse_loss = nn.MSELoss()
def forward(self, student_logits, teacher_logits, student_features, teacher_features, labels):
# Standard distillation loss
ce_loss = self.ce_loss(student_logits, labels)
teacher_probs = F.softmax(teacher_logits / self.temperature, dim=1)
student_log_probs = F.log_softmax(student_logits / self.temperature, dim=1)
kl_loss = self.kl_loss(student_log_probs, teacher_probs) * (self.temperature ** 2)
# Feature distillation loss
feature_loss = self.mse_loss(student_features, teacher_features)
total_loss = (1 - self.alpha - self.beta) * ce_loss + self.alpha * kl_loss + self.beta * feature_loss
return total_loss, ce_loss, kl_loss, feature_loss2. Attention Transfer
class AttentionTransferLoss(nn.Module):
"""Transfer attention maps from teacher to student"""
def __init__(self, p=2):
super().__init__()
self.p = p
def attention_map(self, feature_map):
# Compute attention as the L2 norm across channels
return torch.norm(feature_map, p=self.p, dim=1, keepdim=True)
def forward(self, student_features, teacher_features):
student_attention = self.attention_map(student_features)
teacher_attention = self.attention_map(teacher_features)
# Normalize attention maps
student_attention = F.normalize(student_attention.view(student_attention.size(0), -1))
teacher_attention = F.normalize(teacher_attention.view(teacher_attention.size(0), -1))
return F.mse_loss(student_attention, teacher_attention)3. Progressive Knowledge Distillation
class ProgressiveDistillation:
"""Gradually increase distillation weight during training"""
def __init__(self, initial_alpha=0.1, final_alpha=0.9, warmup_epochs=20):
self.initial_alpha = initial_alpha
self.final_alpha = final_alpha
self.warmup_epochs = warmup_epochs
def get_alpha(self, epoch):
if epoch < self.warmup_epochs:
alpha = self.initial_alpha + (self.final_alpha - self.initial_alpha) * (epoch / self.warmup_epochs)
else:
alpha = self.final_alpha
return alphaHyperparameter Guidelines
Temperature (T)
- Low (1-2): Hard targets, less knowledge transfer
- Medium (3-5): Balanced knowledge transfer (recommended)
- High (6-10): Very soft targets, may lose important information
Alpha (α)
- 0.1-0.3: Focus on ground truth labels
- 0.5-0.7: Balanced approach (recommended)
- 0.8-0.9: Heavy focus on teacher knowledge
Learning Rate
- Start with same LR as baseline training
- Consider lower LR for student to avoid overfitting to teacher
- Use learning rate scheduling
Best Practices
- Teacher Quality: Ensure teacher model is well-trained and robust
- Architecture Matching: Student should have similar structure but smaller capacity
- Temperature Tuning: Experiment with different temperature values
- Regularization: Use dropout and weight decay to prevent overfitting
- Evaluation: Compare against baseline student training
- Multi-Teacher: Consider ensemble of teachers for better knowledge transfer
Common Issues and Solutions
Problem: Student performs worse than baseline
Solutions:
- Reduce temperature value
- Decrease alpha (give more weight to ground truth)
- Check teacher model quality
- Ensure proper normalization
Problem: Slow convergence
Solutions:
- Increase learning rate
- Use progressive distillation
- Warm up the distillation loss
- Check gradient flow
Problem: Overfitting to teacher
Solutions:
- Add regularization
- Reduce alpha value
- Use data augmentation
- Early stopping based on validation loss
This comprehensive guide provides both theoretical understanding and practical implementation of student-teacher networks in PyTorch, with advanced techniques and troubleshooting tips for successful knowledge distillation.