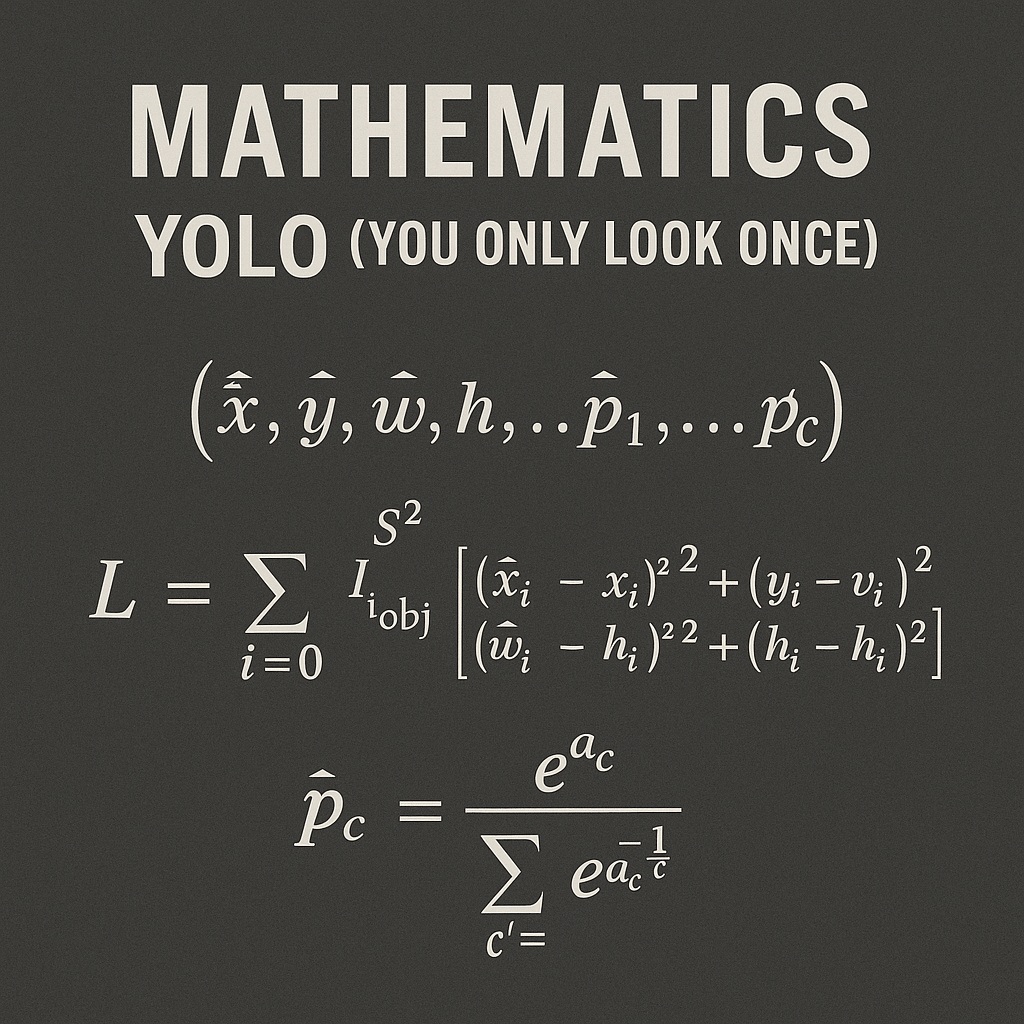Introduction
In the rapidly evolving world of computer vision and artificial intelligence, few innovations have been as transformative as YOLO (You Only Look Once). This revolutionary object detection algorithm has fundamentally changed how computers “see” and understand images, making real-time object detection accessible to developers, researchers, and businesses worldwide.
YOLO represents a paradigm shift from traditional object detection methods, offering unprecedented speed without significantly compromising accuracy. Whether you’re a student exploring computer vision, a developer building AI applications, or simply curious about how machines can identify objects in images, this guide will take you through everything you need to know about YOLO.
What is YOLO?
YOLO, which stands for “You Only Look Once,” is a state-of-the-art object detection algorithm that can identify and locate multiple objects within an image in real-time. Unlike traditional methods that examine an image multiple times to detect objects, YOLO processes the entire image in a single forward pass through a neural network, hence the name “You Only Look Once.”
The algorithm doesn’t just identify what objects are present in an image; it also determines their precise locations by drawing bounding boxes around them. This dual capability of classification and localization makes YOLO incredibly powerful for a wide range of applications.
The Problem YOLO Solves
Before YOLO, object detection was a complex, multi-step process that was both computationally expensive and time-consuming. Traditional approaches like R-CNN (Region-based Convolutional Neural Networks) would:
- Generate thousands of potential object regions in an image
- Run a classifier on each region separately
- Post-process the results to eliminate duplicates
This approach, while accurate, was incredibly slow. Processing a single image could take several seconds, making real-time applications virtually impossible.
YOLO revolutionized this by treating object detection as a single regression problem. Instead of looking at an image multiple times, YOLO divides the image into a grid and predicts bounding boxes and class probabilities for each grid cell simultaneously.
How YOLO Works: The Core Concept
Grid-Based Approach
YOLO divides an input image into an S×S grid (commonly 7×7 or 13×13). Each grid cell is responsible for detecting objects whose centers fall within that cell. This approach ensures that every part of the image is examined exactly once.
Bounding Box Prediction
For each grid cell, YOLO predicts:
- B bounding boxes (typically 2 or 3 per cell)
- Confidence scores for each bounding box
- Class probabilities for each grid cell
Each bounding box consists of five values:
- x, y: Center coordinates of the box (relative to the grid cell)
- width, height: Dimensions of the box (relative to the entire image)
- Confidence score: Probability that the box contains an object
Class Prediction
Each grid cell also predicts the probability of each object class (person, car, dog, etc.) being present in that cell. This creates a comprehensive understanding of both what objects are present and where they’re located.
Network Architecture
The YOLO network is based on a convolutional neural network (CNN) architecture. The original YOLO used a modified version of the GoogLeNet architecture, but subsequent versions have evolved to use more efficient designs.
The network consists of:
- Convolutional layers for feature extraction
- Fully connected layers for prediction
- Output layer that produces the final detection results
Evolution of YOLO: From v1 to v8
YOLOv1 (2015)
The original YOLO introduced the revolutionary single-shot detection concept. While groundbreaking, it had limitations in detecting small objects and struggled with objects that were close together.
YOLOv2 (2016)
Also known as YOLO9000, this version introduced:
- Batch normalization for improved training
- Anchor boxes for better bounding box predictions
- Higher resolution training
- Multi-scale training for robustness
YOLOv3 (2018)
Significant improvements included:
- Feature Pyramid Networks (FPN) for better multi-scale detection
- Logistic regression for object confidence
- Multi-label classification capability
- Darknet-53 backbone for improved feature extraction
YOLOv4 (2020)
Focused on optimization and practical improvements:
- CSPDarkNet53 backbone
- SPP (Spatial Pyramid Pooling) block
- PANet path aggregation
- Extensive use of data augmentation techniques
YOLOv5 (2020)
Developed by Ultralytics, not the original authors:
- PyTorch implementation for easier use
- Improved training procedures
- Better model scaling
- Enhanced user experience and documentation
YOLOv6-v8 (2021-2023)
Continued refinements focusing on:
- Improved accuracy-speed trade-offs
- Better mobile and edge device support
- Enhanced training techniques
- More robust architectures
Key Advantages of YOLO
YOLO’s main advantages make it ideal for real-time applications:
- Speed: Single-pass approach enables real-time processing
- Global Context: Sees entire image for better understanding
- Simplicity: Unified architecture for easy implementation
- End-to-End Training: Optimizes entire pipeline jointly
Speed
YOLO’s single-pass approach makes it incredibly fast. Modern versions can process images at 30+ frames per second on standard hardware, enabling real-time applications.
Global Context
Unlike sliding window approaches, YOLO sees the entire image during training and testing, allowing it to understand global context and make more informed predictions.
Generalization
YOLO learns generalizable representations of objects, making it perform well on new, unseen images and different domains.
Simplicity
The unified architecture makes YOLO easier to understand, implement, and modify compared to multi-stage detection systems.
End-to-End Training
The entire detection pipeline can be optimized jointly, leading to better overall performance.
Common Applications
Autonomous Vehicles
YOLO is widely used in self-driving cars to detect pedestrians, other vehicles, traffic signs, and road obstacles in real-time.
Security and Surveillance
Security systems use YOLO to detect unauthorized persons, suspicious activities, or specific objects in video feeds.
Retail and Inventory Management
Stores use YOLO for automated checkout systems, inventory tracking, and customer behavior analysis.
Sports Analytics
YOLO tracks players, balls, and other objects in sports videos for performance analysis and automated highlighting.
Medical Imaging
In healthcare, YOLO assists in detecting anomalies in medical images, though this requires specialized training and validation.
Industrial Automation
Manufacturing uses YOLO for quality control, defect detection, and automated sorting systems.
Getting Started with YOLO
Prerequisites
- Basic understanding of machine learning concepts
- Familiarity with Python programming
- Understanding of computer vision fundamentals
- Knowledge of deep learning frameworks (PyTorch or TensorFlow)
Installation
The easiest way to get started is with YOLOv5 or YOLOv8 using Ultralytics:
pip install ultralyticsBasic Usage Example
from ultralytics import YOLO
# Load a pre-trained model
model = YOLO('yolov8n.pt')
# Run inference on an image
results = model('path/to/image.jpg')
# Display results
results[0].show()Training on Custom Data
Before training on custom data, ensure you have:
- Prepared dataset in YOLO format
- Configuration file specifying classes and paths
- Adequate computational resources for training
- Validation strategy for model evaluation
- Prepare your dataset in YOLO format
- Create a configuration file specifying classes and paths
- Train the model using the provided training scripts
- Evaluate and fine-tune the model performance
Understanding YOLO Output
Bounding Boxes
Each detected object is represented by a bounding box with coordinates (x, y, width, height) and a confidence score.
Class Predictions
Each bounding box includes class probabilities indicating what type of object was detected.
Confidence Scores
These indicate how certain the model is about the detection. Higher scores mean more confident detections.
Common Challenges and Solutions
Small Object Detection
- Challenge: YOLO traditionally struggles with very small objects.
- Solution: Use higher resolution inputs, multi-scale training, and feature pyramid networks.
Overlapping Objects
- Challenge: Objects that overlap significantly can be difficult to detect separately.
- Solution: Non-maximum suppression and improved anchor box strategies help address this.
Class Imbalance
- Challenge: Some object classes may be underrepresented in training data.
- Solution: Use data augmentation, balanced sampling, and focal loss techniques.
Domain Adaptation
- Challenge: Models trained on one type of data may not work well on different domains.
- Solution: Transfer learning, domain adaptation techniques, and diverse training data.
Best Practices for YOLO Implementation
Data Preparation
- Ensure high-quality, diverse training data
- Use proper annotation tools and formats
- Implement data augmentation techniques
- Maintain balanced class distributions
Training Optimization
- Start with pre-trained weights
- Use appropriate learning rates and schedules
- Monitor training metrics carefully
- Implement early stopping to prevent overfitting
Model Selection
- Choose the right YOLO version for your speed-accuracy requirements
- Consider model size constraints for deployment
- Evaluate different backbone architectures
Post-Processing
- Tune non-maximum suppression parameters
- Set appropriate confidence thresholds
- Implement tracking for video applications
Performance Metrics
Mean Average Precision (mAP)
The primary metric for evaluating object detection performance, measuring accuracy across different confidence thresholds.
Intersection over Union (IoU)
Measures the overlap between predicted and ground truth bounding boxes.
Frames Per Second (FPS)
Measures the speed of the detection system, crucial for real-time applications.
Model Size
Important for deployment on resource-constrained devices.
Future Trends and Developments
The future of YOLO and object detection includes:
- Transformer-based architectures for improved attention mechanisms
- Mobile optimization for edge deployment
- Multi-modal detection combining visual and other data
- Self-supervised learning to reduce labeling requirements
Transformer-Based Architectures
Integration of transformer models for improved feature extraction and attention mechanisms.
Mobile and Edge Optimization
Continued focus on making YOLO more efficient for mobile and edge devices.
Multi-Modal Detection
Combining visual information with other modalities like text or audio.
Improved Small Object Detection
Advanced techniques for detecting very small objects in high-resolution images.
Self-Supervised Learning
Reducing dependence on labeled data through self-supervised training approaches.
Conclusion
YOLO has democratized object detection by making it fast, accurate, and accessible to developers worldwide. Its evolution from the original 2015 paper to the latest versions demonstrates the rapid pace of innovation in computer vision.
Understanding YOLO opens doors to numerous applications across industries, from autonomous vehicles to retail analytics. The algorithm’s simplicity, combined with its powerful capabilities, makes it an essential tool in the modern AI toolkit.
As you begin your journey with YOLO, remember that practical experience is invaluable. Start with pre-trained models, experiment with different versions, and gradually work toward training custom models for your specific use cases. The computer vision community continues to push the boundaries of what’s possible with object detection, and YOLO remains at the forefront of these exciting developments.
Whether you’re building the next generation of smart cameras, developing autonomous systems, or simply exploring the fascinating world of computer vision, YOLO provides a solid foundation for understanding how machines can see and interpret the world around us.
Appendix: Additional Resources
Useful Links
Code Examples
Additional code examples and tutorials can be found in the project repository.