Vision Transformers (ViT): A Simple Guide
Introduction
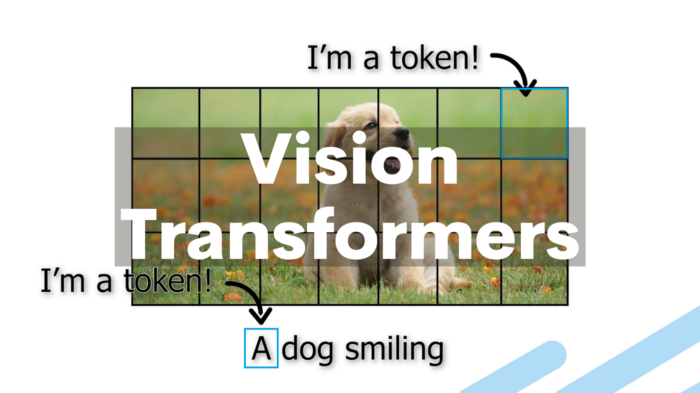
Vision Transformers (ViTs) represent a paradigm shift in computer vision, adapting the transformer architecture that revolutionized natural language processing for image classification and other visual tasks. Instead of relying on convolutional neural networks (CNNs), ViTs treat images as sequences of patches, applying the self-attention mechanism to understand spatial relationships and visual features.
Background: From CNNs to Transformers
Traditional computer vision relied heavily on Convolutional Neural Networks (CNNs), which process images through layers of convolutions that detect local features like edges, textures, and patterns. While effective, CNNs have limitations in capturing long-range dependencies across an image due to their local receptive fields.
Transformers, originally designed for language tasks, excel at modeling long-range dependencies through self-attention mechanisms. The key insight behind Vision Transformers was asking: “What if we could apply this powerful attention mechanism to images?”
Core Concept: Images as Sequences
The fundamental innovation of ViTs lies in treating images as sequences of patches rather than pixel grids. Here’s how this transformation works:
Image Patch Embedding
- Patch Division: An input image (typically 224×224 pixels) is divided into fixed-size patches (commonly 16×16 pixels), resulting in a sequence of patches
- Linear Projection: Each patch is flattened into a vector and linearly projected to create patch embeddings
- Position Encoding: Since transformers don’t inherently understand spatial relationships, positional encodings are added to maintain spatial information
- Classification Token: A special learnable [CLS] token is prepended to the sequence, similar to BERT’s approach
Mathematical Formulation
For an image of size H×W×C divided into patches of size P×P:
- Number of patches: N = (H×W)/P²
- Each patch becomes a vector of size P²×C
- After linear projection: embedding dimension D
Architecture Components
1. Patch Embedding Layer
The patch embedding layer converts image patches into token embeddings that the transformer can process. This involves:
- Reshaping patches into vectors
- Linear transformation to desired embedding dimension
- Adding positional encodings
2. Transformer Encoder
The core of ViT consists of standard transformer encoder blocks, each containing:
- Multi-Head Self-Attention (MSA): Allows patches to attend to all other patches
- Layer Normalization: Applied before both attention and MLP layers
- Multi-Layer Perceptron (MLP): Two-layer feedforward network with GELU activation
- Residual Connections: Skip connections around both attention and MLP blocks
3. Classification Head
The final component extracts the [CLS] token’s representation and passes it through:
- Layer normalization
- Linear classifier to produce class predictions
Self-Attention in Vision
The self-attention mechanism in ViTs operates differently from CNNs:
Attention Maps
- Each patch can attend to every other patch in the image
- Attention weights reveal which parts of the image are most relevant for classification
- This enables modeling of long-range spatial dependencies
Global Context
Unlike CNNs that build up receptive fields gradually, ViTs have global receptive fields from the first layer, allowing immediate access to information across the entire image.
Training Considerations
Data Requirements
Vision Transformers typically require large amounts of training data to perform well:
- Pre-training: Often trained on large datasets like ImageNet-21k or JFT-300M
- Fine-tuning: Then adapted to specific tasks with smaller datasets
- Data Efficiency: ViTs can be less data-efficient than CNNs when training from scratch
Optimization Challenges
- Initialization: Careful weight initialization is crucial
- Learning Rate: Often requires different learning rates for different components
- Regularization: Techniques like dropout and weight decay are important
- Warmup: Learning rate warmup is commonly used
Variants and Improvements
ViT Variants
- ViT-B/16, ViT-L/16, ViT-H/14: Different model sizes with varying patch sizes
- DeiT (Data-efficient ViT): Improved training strategies for smaller datasets
- Swin Transformer: Hierarchical vision transformer with shifted windows
- CaiT: Class-Attention in Image Transformers with separate class attention
Architectural Improvements
- Hierarchical Processing: Multi-scale feature extraction
- Local Attention: Restricting attention to local neighborhoods
- Hybrid Models: Combining CNN features with transformer processing
Advantages of Vision Transformers
Strengths
- Long-range Dependencies: Natural ability to model global relationships
- Interpretability: Attention maps provide insights into model decisions
- Scalability: Performance improves with larger models and datasets
- Transfer Learning: Excellent pre-trained representations
- Architectural Simplicity: Unified architecture for various vision tasks
Performance Benefits
- State-of-the-art results on image classification
- Strong performance on object detection and segmentation when adapted
- Excellent transfer learning capabilities across domains
Limitations and Challenges
Current Limitations
- Data Hunger: Requires large datasets for optimal performance
- Computational Cost: High memory and compute requirements
- Inductive Bias: Lacks CNN’s built-in spatial inductive biases
- Small Dataset Performance: Can underperform CNNs on limited data
Ongoing Research Areas
- Improving data efficiency
- Reducing computational requirements
- Better integration of spatial inductive biases
- Hybrid CNN-Transformer architectures
Applications Beyond Classification
Computer Vision Tasks
- Object Detection: DETR (Detection Transformer) applies transformers to detection
- Semantic Segmentation: Segmentation transformers for pixel-level predictions
- Image Generation: Vision transformers in generative models
- Video Analysis: Extending to temporal sequences
Multimodal Applications
- Vision-Language Models: CLIP and similar models combining vision and text
- Visual Question Answering: Integrating visual and textual understanding
- Image Captioning: Generating descriptions from visual content
Implementation Considerations
Model Selection
Choose ViT variants based on:
- Available computational resources
- Dataset size and characteristics
- Required inference speed
- Target accuracy requirements
Training Strategy
- Use pre-trained models when possible
- Apply appropriate data augmentation
- Consider knowledge distillation for smaller models
- Monitor for overfitting, especially on smaller datasets
Optimization Tips
- Use mixed precision training to reduce memory usage
- Implement gradient checkpointing for large models
- Consider model parallelism for very large architectures
- Apply appropriate regularization techniques
Future Directions
Research Trends
- Efficiency Improvements: Making ViTs more computationally efficient
- Architecture Search: Automated design of vision transformer architectures
- Self-Supervised Learning: Reducing dependence on labeled data
- Unified Architectures: Single models handling multiple vision tasks
Emerging Applications
- Real-time vision applications
- Mobile and edge deployment
- Scientific imaging and medical applications
- Autonomous systems and robotics
Conclusion
Vision Transformers represent a fundamental shift in computer vision, demonstrating that the transformer architecture’s success in NLP can extend to visual tasks. While they present challenges in terms of data requirements and computational cost, their ability to model long-range dependencies and achieve state-of-the-art performance makes them a crucial tool in modern computer vision.
The field continues to evolve rapidly, with ongoing research addressing current limitations while exploring new applications. As the technology matures, we can expect ViTs to become increasingly practical for a wider range of real-world applications, potentially reshaping how we approach visual understanding tasks.
Understanding Vision Transformers is essential for anyone working in modern computer vision, as they represent not just a new model architecture, but a new way of thinking about how machines can understand and process visual information.