Introduction
Mixture of Experts (MoE) represents a fundamental paradigm shift in machine learning architecture design, offering a scalable approach to building models that can handle complex, heterogeneous tasks while maintaining computational efficiency. This architectural pattern has gained significant traction in recent years, particularly in the realm of large language models and neural networks, where the ability to scale model capacity without proportionally increasing computational costs has become paramount.
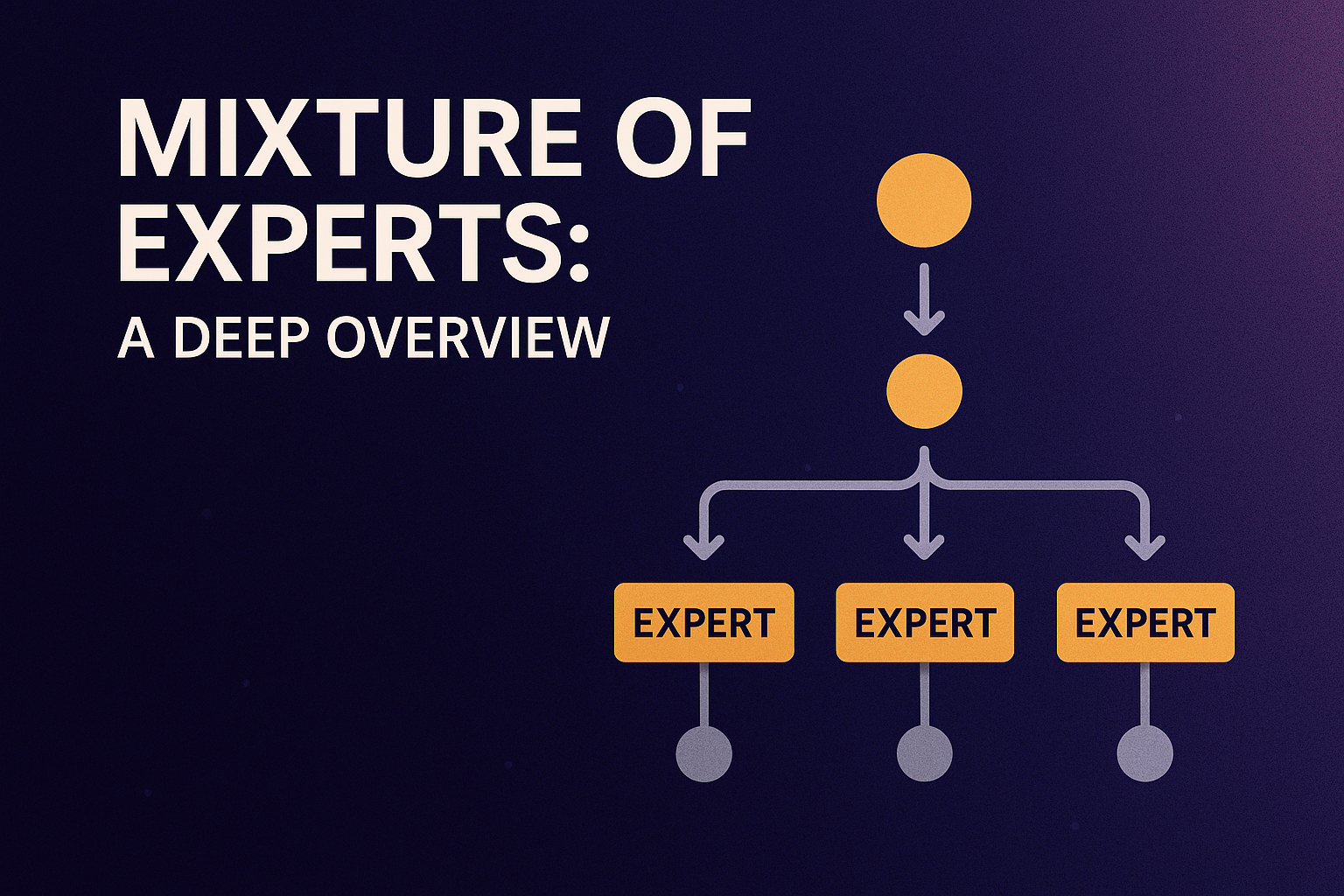
The core insight behind MoE lies in the principle of specialization: rather than training a single monolithic model to handle all aspects of a task, we can train multiple specialized “expert” models, each focusing on different aspects or subdomains of the problem space. A gating mechanism then learns to route inputs to the most appropriate experts, creating a system that can be both highly specialized and broadly capable.
The fundamental principle of MoE is specialization: multiple expert models focus on different aspects of a problem, coordinated by a learned gating mechanism.
Historical Context and Evolution
The concept of mixture models has deep roots in statistics and machine learning, dating back to the 1960s with early work on mixture distributions. However, the specific formulation of Mixture of Experts as we understand it today emerged in the 1990s through the pioneering work of researchers like Robert Jacobs, Steven Nowlan, and Geoffrey Hinton.
The original MoE framework was motivated by the observation that many learning problems naturally decompose into subproblems that might be better solved by different models. For instance, in a classification task involving multiple classes, different regions of the input space might benefit from different decision boundaries or feature representations. This led to the development of the classical MoE architecture, which combined multiple expert networks with a gating network that learned to weight their contributions.
Modern Resurgence
The resurgence of interest in MoE architectures in recent years can be attributed to several factors:
- Model scaling challenges: The explosion in model sizes, particularly in NLP
- Computational efficiency: Need for sublinear scaling methods
- Hardware improvements: Better support for sparse computation
- Theoretical advances: Better understanding of training dynamics
Fundamental Architecture
Core Components
The MoE architecture consists of three fundamental components that work in concert to create a flexible and efficient learning system.
Expert Networks form the foundation of the MoE system. These are typically neural networks, though they can be any differentiable function approximator. Each expert is designed to become specialized in handling specific types of inputs or solving particular aspects of the overall task.
Key characteristics:
- Can be identical in architecture but differ in parameters
- May have fundamentally different architectures
- Optimize for different input patterns or computational requirements
Gating Network serves as the routing mechanism that determines which experts should be activated for a given input. This network learns to predict the probability distribution over experts, effectively learning which expert or combination of experts is most likely to produce the best output.
Objectives:
- Route inputs to appropriate experts
- Balance computational load across experts
- Maintain end-to-end trainability
Combination Mechanism determines how outputs from multiple experts are combined to produce the final prediction. The most common approach is a weighted combination, where the gating network’s output serves as the weights.
Approaches:
- Weighted combination (most common)
- Attention-based mechanisms
- Learned combination functions
Mathematical Formulation
The mathematical foundation of MoE can be expressed elegantly through probabilistic modeling. Given an input vector \(\mathbf{x}\), the MoE model computes its output as:
\[\mathbf{y} = \sum_{i=1}^{N} g_i(\mathbf{x}) \cdot E_i(\mathbf{x})\]
Where: - \(g_i(\mathbf{x})\) represents the gating function’s output for expert \(i\) - \(E_i(\mathbf{x})\) represents the output of expert \(i\)
The gating function typically uses a softmax activation:
\[g_i(\mathbf{x}) = \frac{\exp(\mathbf{W}_g \mathbf{x} + \mathbf{b}_g)_i}{\sum_{j=1}^{N} \exp(\mathbf{W}_g \mathbf{x} + \mathbf{b}_g)_j}\]
The training objective includes multiple components:
\[\mathcal{L} = \mathcal{L}_{\text{prediction}} + \lambda \mathcal{L}_{\text{load balancing}} + \mu \mathcal{L}_{\text{expert regularization}}\]
Example MoE Implementation
import torch
import torch.nn as nn
import torch.nn.functional as F
class MixtureOfExperts(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_experts, top_k=2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
# Gating network
self.gate = nn.Linear(input_dim, num_experts)
# Expert networks
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim)
) for _ in range(num_experts)
])
def forward(self, x):
# Gating scores
gate_scores = self.gate(x)
gate_probs = F.softmax(gate_scores, dim=-1)
# Select top-k experts
top_k_probs, top_k_indices = torch.topk(gate_probs, self.top_k, dim=-1)
# Normalize top-k probabilities
top_k_probs = top_k_probs / top_k_probs.sum(dim=-1, keepdim=True)
# Compute expert outputs
expert_outputs = []
for i, expert in enumerate(self.experts):
expert_outputs.append(expert(x))
# Combine outputs
output = torch.zeros_like(expert_outputs[0])
for i in range(self.top_k):
expert_idx = top_k_indices[:, i]
weight = top_k_probs[:, i].unsqueeze(-1)
for j, expert_output in enumerate(expert_outputs):
mask = (expert_idx == j).float().unsqueeze(-1)
output += weight * mask * expert_output
return outputTraining Dynamics and Optimization
Training MoE systems presents unique challenges that distinguish it from traditional neural network training. The primary challenge lies in the discrete nature of expert selection combined with the need for end-to-end differentiable training.
Gradient Flow and Backpropagation
The gating mechanism creates a complex gradient flow pattern. When the gating network routes an input primarily to a subset of experts, the gradients flow mainly through those active experts. This can lead to training instabilities where some experts receive very few training examples, potentially leading to underfitting, while others become overutilized.
The soft gating approach helps mitigate gradient flow issues but increases computational overhead as multiple experts must be evaluated for each input.
Load Balancing and Expert Utilization
One of the most critical challenges in MoE training is ensuring balanced utilization of experts. Without proper load balancing, the system may collapse to using only a few experts, essentially reducing the model to a smaller capacity system.
Solutions for load balancing:
- Auxiliary losses that penalize uneven expert utilization
- Noise injection in the gating network to encourage exploration
- Curriculum learning approaches for gradual expert specialization
Sparsity and Efficiency
A key advantage of MoE systems is their ability to maintain sparsity during inference. By activating only a subset of experts for each input, computational cost can be kept relatively low even as the total number of parameters increases.
The choice of \(k\) in top-\(k\) gating represents a fundamental trade-off:
| Small \(k\) | Large \(k\) |
|---|---|
| More efficient inference | Higher computational cost |
| Limited expressiveness | Greater model capacity |
| Faster training | More complex optimization |
Applications and Use Cases
Natural Language Processing
MoE has found particularly strong application in natural language processing, where the heterogeneous nature of language tasks makes expert specialization highly beneficial. Large language models like GPT-3 and subsequent models have incorporated MoE architectures to scale to trillions of parameters while maintaining reasonable computational costs.
Expert specialization in NLP:
- Syntactic constructions
- Numerical information processing
- Domain-specific terminology
- Language-specific patterns (in multilingual models)
Computer Vision
In computer vision, MoE architectures have been applied to tasks ranging from image classification to object detection and segmentation. The visual domain’s inherent structure makes it well-suited for expert specialization.
Applications in vision:
- Object detection with size/category-specific experts
- Image segmentation with boundary/texture specialists
- Vision transformers with spatial attention experts
Multimodal Learning
MoE architectures are particularly well-suited for multimodal learning tasks, where inputs might come from different modalities (text, images, audio, etc.). Different experts can specialize in processing different modalities or in handling the fusion of information across modalities.
Advanced Techniques and Variants
Hierarchical Mixture of Experts
Hierarchical MoE extends the basic MoE concept by organizing experts in a tree-like structure. This approach allows for more efficient routing and can capture hierarchical patterns in the data.
graph LR
A[Input] --> B[Level 1 Gate]
B --> C[Expert Cluster 1]
B --> D[Expert Cluster 2]
B --> E[Expert Cluster 3]
C --> F[Expert 1.1]
C --> G[Expert 1.2]
D --> H[Expert 2.1]
D --> I[Expert 2.2]
E --> J[Expert 3.1]
E --> K[Expert 3.2]
Sparse Mixture of Experts
Sparse MoE focuses on maximizing the efficiency benefits of expert sparsity. These systems typically activate only a very small fraction of available experts for each input.
Example: Switch Transformer
- Activates only one expert per input
- Enables very efficient scaling
- Requires careful design for single-expert effectiveness
Adaptive Mixture of Experts
Adaptive MoE systems dynamically adjust their architecture based on input or task requirements:
- Dynamic expert count adjustment
- Architecture modification based on context
- Computational resource adaptation
Challenges and Limitations
Training Stability
Training MoE systems can be significantly more challenging than training traditional neural networks. The interaction between the gating network and expert networks creates a complex optimization landscape.
Common issues:
- Mode collapse (using only subset of experts)
- Gradient flow problems
- Training instabilities
Computational Overhead
While MoE systems can achieve sublinear scaling in terms of computational cost per parameter, they often have higher absolute computational costs than smaller traditional models.
Overhead sources:
- Gating network computation
- Multiple expert evaluation
- Memory requirements for all expert parameters
Expert Specialization vs. Generalization
The balance between expert specialization and generalization represents a fundamental challenge in MoE design. This is particularly acute in dynamic environments where the input distribution may shift over time.
Recent Developments and State-of-the-Art
Large-Scale Language Models
The most prominent recent application of MoE has been in large-scale language models:
- PaLM: Pathways Language Model with MoE scaling
- GLaM: Generalist Language Model with efficient MoE
- GPT variants: Various GPT models with MoE components
Efficient Training Methods
Recent research has focused on developing more efficient training methods:
- Better load balancing techniques
- More stable training procedures
- Reduced gating mechanism overhead
- Expert parallelism for distributed training
Integration with Other Techniques
MoE is increasingly being combined with other advanced techniques:
- Attention mechanisms
- Normalization methods
- Architectural innovations
- Transformer architectures
Future Directions and Research Opportunities
Automated Expert Design
Current MoE systems typically use manually designed expert architectures. Future research directions include:
- Neural architecture search for MoE
- Task-specific expert design
- Automated capacity allocation
Dynamic Expert Creation
Rather than having a fixed set of experts, future systems might:
- Dynamically create and remove experts
- Adapt to evolving task requirements
- Respond to changing data distributions
Theoretical Understanding
Despite practical success, theoretical understanding remains limited:
- When and why MoE systems work well
- Optimal design principles
- Convergence guarantees
- Generalization bounds
Hardware Co-design
The unique computational patterns of MoE systems suggest opportunities for specialized hardware:
- MoE-optimized processors
- Efficient sparse computation
- Memory hierarchy optimization
- Distributed computing architectures
Conclusion
Mixture of Experts represents a powerful paradigm for building scalable and efficient machine learning systems. By leveraging the principle of specialization, MoE systems can achieve remarkable performance while maintaining computational efficiency.
Key takeaways:
- Scalability: MoE enables sublinear scaling of computational cost with model capacity
- Specialization: Expert networks can focus on specific aspects of complex tasks
- Efficiency: Sparse activation patterns reduce computational overhead
- Challenges: Training stability and load balancing remain significant hurdles
- Future potential: Continued innovation in architectures, training methods, and hardware
The success of MoE in recent large-scale language models demonstrates its potential for enabling the next generation of AI systems. As our understanding deepens and techniques improve, MoE will likely play an increasingly important role in advanced AI system development across diverse domains.
The combination of MoE with other advanced techniques and the development of specialized hardware will likely drive continued innovation in this space, making AI systems both more capable and more efficient.
This document provides a comprehensive overview of Mixture of Experts architectures, from theoretical foundations to practical applications and future directions. For the latest developments in this rapidly evolving field, readers are encouraged to consult recent research publications and conference proceedings.